ConfyUI初见
得益于公司数据AI团队的努力,我(shen shou dang)不费吹灰之力可以坐享其成。
今天介绍一下ConfyUI。ConfyUI是一套UI,用知乎上的话来说就是目前功能最强大、使用最自由的扩散图形用户界面和后台。
使用ConfyUI可以方便的实现文生图,图生图,图生动图,图生视频等效果。
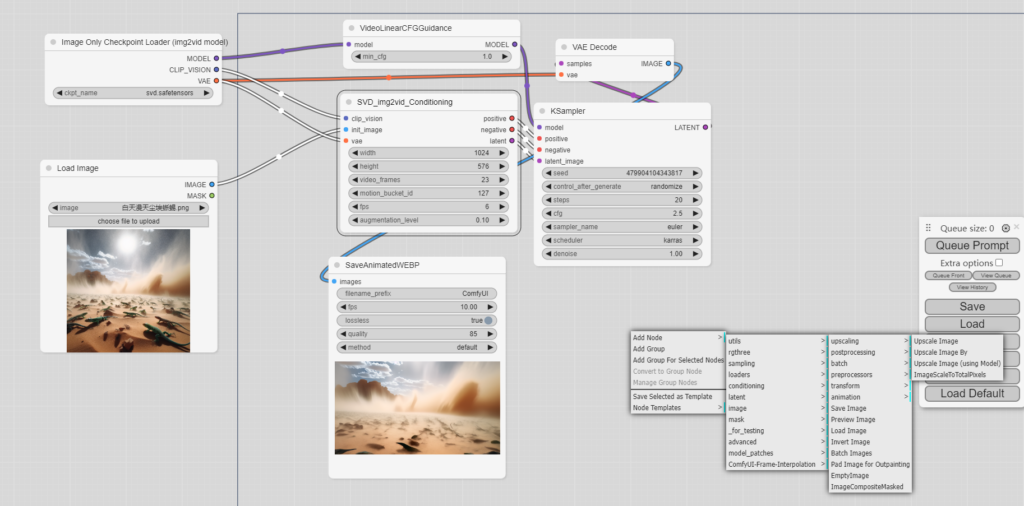
具体的使用方法,就是类似构建一个pipeline,定义好输入输出,安装好必要的模型,插件。然后拖拉拽把它们全部连起来。
那动手做做看吧。我们试试图生视频。
图片来自私有化的Stable Diffusion。通过简单的文字描述来生成图片。AI的发挥有波动,我们提供的咒语要尽可能丰富、精确。
得到图片后,在下图pipeline的起点Load进去,checkpoint模块选择合适的模型,比如svd(Stable Video Diffusion)或者svd_xt(区别在于生成视频的帧数多少),修改freeu的权重,然后点击添加到队列,等待生成就可以了。
在最终的输出方面,可以生成为webp,gif,也可以结合video combine生成几秒钟的视频。